03日目: データモデル
テキストエディターを開いて Perl コードを書きたい方は、今日のチュートリアルで開発を進めることを知ったら幸せになるでしょう。 Jobeet のデータモデルを定義し、データベースとの情報のやりとりに ORM を使い、アプリケーションの最初のモジュールを作成します。
Ark 自体にはデータベースにアクセスする機能はありませんが、その代わり、任意のモジュールをモデルとして使用できる機能があります。 そのため、データベースアクセスにはどんな ORM でも使用することが出来ます。
今回は現在 Perl でデファクトスタンダードな ORM である DBIx::Class を使用しデータモデルを構築してみましょう。
従って本日は Ark というよりは DBIx::Class のチュートリアルともいえます。
依存モジュール
DBIx::Class の他に、本日はもう一つ、SQL::Translator というモジュールが必要なので CPAN の復習もかねて最初にこれらのモジュールをインストールしておきましょう。
$ cpanm DBIx::Class SQL::Translator
さて、今、あなたのアプリケーションで使う2つのCPANモジュールを新たにインストールしました。こういう時は、 Makefile.PL に依存モジュールの記述を以下のように追加しておきましょう。
requires 'DBIx::Class';
requires 'SQL::Translator';
いちいち記載するのが手間に感じるかもしれませんが、これは後々あなたを大いに助けることになります。
別の環境(それは本番環境かもしれません!)にアプリケーションをセットアップする際にまたCPANモジュールを全て入れる必要があります。 CPANモジュールのインストール漏れがあったら大変です。
しかし、心配することはありません。Makefile.PL にきちんと依存モジュールを記載しておけば、以下のコマンド一発で魔法のように 全てのCPANモジュールをインストールしてくれます。
$ cpanm --installdeps .
Why DBIx::Class ?
えっ、DBIx::Class?と思われるかもしれません。かつては一斉を風靡したDBIx::Classですが、日本のPerl界隈ではDBIx::Classはあまり好ましいモジュールでは
なくなってきています。
曰く、
- オブジェクトを大量に生成するため重い
- クエリ発行のタイミングがわかりづらい
- 余計な挙動をする
- ソースコードが大きすぎて読めない
- 上記を避けるためのバッドノウハウも覚えなくてはいけない
等々。全て正しいです。
しかし、以下のメリットがそれらを上回ります。
- 枯れている
- 多くの便利なプラグインが存在する
- 世界中で使われており、バグレポートや修正要望が積極的に寄せられている
- 今もなお、優秀な複数のメンテナがメンテナンスを続けている
プラグインという点では特に DBIx::Class::Schema::Versioned が便利です。これはスキーマを随時変更しながら 長期運用をすることを考えると、欠かせないモジュールとなっています。 (これがあるから離れられないという噂もあります)
他にもORMの選択肢はありますが、1日目の Ark の説明でも述べたとおり、軽量かつあまり枯れて いないモジュールを使う場合は、必要に応じて自分でソースを読み、足りない機能があったら モジュールやプラグインを自分で書いたりすることが求められてしまいます。
それに、今後ORMを乗り換えたとしても(遠くない将来そうなるでしょう)、DBIx::Classの流儀を 知っておくことは損ではありません。
DBIx::Class は本当に何でもできます。余計に思える機能もたくさんあります。
「こんなこともできてしまうのか」と驚かされることもあります。
多機能という点ではピークとも言えるでしょう。
それは今後、新しいORMが作られる中でも使っていく上でも、ベンチマークとなることは間違いありません。
2011年現在、DBIx::Classの有力な代替候補はDBIx::Skinnyですが、元々は DBIx::Classのヘビーユーザーだった作者がDBIx::Classに嫌気がさして作り始めた背景があるようです。 良くも悪くも DBIx::Class を受け継いでいる部分があります。
また、DBIx::Skinny の後継として、Teng というORMの開発が進んでいるので、今にDBIx::Class から DBIx::Skinny に乗り換えるよりかは、もう少し様子を見てTengに乗り換えてるのも良いのではないでしょうか。
リレーションモデル
昨日のユーザーストーリーではプロジェクトの主要なオブジェクト: jobs(求人)、affiliates(アフィリエイト)、categories(カテゴリ)を詳しく説明しました。 下図は対応するエンティティ関係図です:
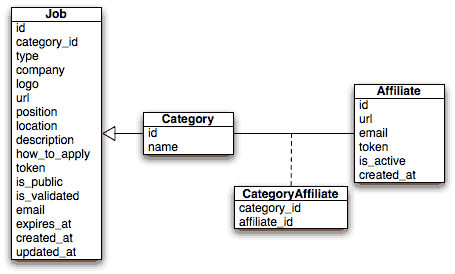
ストーリーで説明したカラムに加えて、いくつかのテーブルには created_at フィールドが追加されています。
このフィールドには、レコードが生成されたときの現在のシステム時刻が DBIx::Class によって自動的にセットされます。
updated_at フィールドも同様です。レコードが更新されたときのシステム時刻がセットされます。
スキーマ
求人、アフィリエイト、カテゴリを保存するために、当然リレーショナルデータベースが必要となります。
しかし Ark はオブジェクト指向のフレームワークですから、可能ならいつでもオブジェクトとして操作したいでしょう。 例えば、データベースからレコードを取得する SQL ステートメントを書くのではなく、オブジェクトを使います。
リレーショナルデータベースの情報をオブジェクトモデルとしてマッピングする必要があります。
このマッピングには ORM ツールを使います。 CPAN にはおびただしい量の ORM モジュールがアップされていますが、 Ark からはそれらすべてを使用することが出来ます。
このチュートリアルでは DBIx::Class を使います。
Schema クラス
DBIx::Class では DBIx::Class::Schema を継承したクラスをベースとなる Schema クラスとして使用します。
Jobeet のための Jobeet::Schema を作成しましょう。
lib/Jobeet/Schema.pm を作成し、以下のように編集してみましょう。
package Jobeet::Schema;
use strict;
use warnings;
use parent 'DBIx::Class::Schema';
use DateTime;
__PACKAGE__->load_namespaces;
my $TZ = DateTime::TimeZone->new(name => 'Asia/Tokyo');
sub TZ {$TZ}
sub now {DateTime->now(time_zone => shift->TZ)}
sub today {shift->now->truncate(to => 'day')}
1;
日付処理用のメソッドも幾つか作成しておきます。明日、ここにバージョニングサポートのコードを付け加えますが、とりあえずこのまま話を進めましょう。
Schema クラスで load_namespaces を呼ぶと DBIx::Class は
Jobeet::Schema::Result::*- Result クラスJobeet::Schema::ResultSet::*- ResultSet クラス
のネームスペースにあるコードを自動ロードします。 Resultクラスとはデータベースのテーブルを表すクラスであり、1テーブルにつき1クラス定義する必要があります。
ResultSet クラスとは同名の Result クラスの集合を表すクラスで、SQL クエリの結果などはこの ResultSet クラスで表されます。こちらの定義は省略可能で、省略された場合、デフォルトの ResultSet クラスが使用されます。
Result クラスの定義
それではさっそく Result クラスを定義していきましょう。テーブルごとに定義する必要があると言いましたね。したがって、ここでは
- Jobeet::Schema::Result::Job
- Jobeet::Schema::Result::Category
- Jobeet::Schema::Result::CategoryAffiliate
- Jobeet::Schema::Result::Affiliate
を定義していきます。
Perl のクラスのファイル名はほとんどの場合パッケージ名から一意に決定されます。 Jobeet::Schema::Result::Job は lib/Jobeet/Schema/Result/Job.pm にと言った具合です。
今後このルールに沿ったファイルはいちいちファイル名を出しませんのでご了承ください。そしてこれから定義する Result セットクラスはすべてこのルールに沿っています。
それでは一つ目の Job クラスを作って行きましょう。
DBIx::Class の Result クラスは、DBIx::Class を継承して作成し、
package Jobeet::Schema::Result::Job;
use strict;
use warnings;
use parent 'DBIx::Class';
__PACKAGE__->load_components(qw/Core/);
# ここにテーブル定義
1;
のような構成になります。Result クラスとして動作するために最低限この Core コンポーネントはロードする必要があります。
他にもさまざまなコンポーネントがありますが、ここではこれに加えて InflateColumn::DateTime コンポーネントもロードするようにしてみましょう。
package Jobeet::Schema::Result::Job;
use strict;
use warnings;
use parent 'DBIx::Class';
__PACKAGE__->load_components(qw/InflateColumn::DateTime Core/);
# ここにテーブル定義
1;
この InflateColumn::DateTime コンポーネントは date 型や datetime 型のデータを取得時に自動で Perl の DateTime オブジェクトに変換してくれたり、逆に DateTime オブジェクトをそのままデータベースに insert することを可能にしてくれるコンポーネントです。
これをすべての Result クラスそれぞれに書くのは面倒ですし無駄です。また DBIx::Class はこのように定義が重複するとパフォーマンスが悪くなります。こういう場合は共通のベースクラスを作成し、定義を一元化させるのが DBIx::Class をつかう上での重要なベストプラクティスとなっています。 そこでこれら共通の処理をまとめ Jobeet::Schema::ResultBase としてベースクラスを定義してみましょう。
package Jobeet::Schema::ResultBase;
use strict;
use warnings;
use parent 'DBIx::Class';
__PACKAGE__->load_components(qw/InflateColumn::DateTime Core/);
1;
そしてこれを使用してさきほどの Job クラスを書き換えると
package Jobeet::Schema::Result::Job;
use strict;
use warnings;
use parent 'Jobeet::Schema::ResultBase';
# ここにテーブル定義
1;
こうなります。シンプルになりましたね。
それでは Job クラスのテーブル定義をしていきましょう。まずは以下のようにテーブル名を定義します:
__PACKAGE__->table('jobeet_job');
そして続けてカラム定義を追加していきます:
__PACKAGE__->add_columns(
id => {
data_type => 'INTEGER',
is_nullable => 0,
is_auto_increment => 1,
extra => {
unsigned => 1,
},
},
category_id => {
data_type => 'INTEGER',
is_nullable => 0,
extra => {
unsigned => 1,
},
},
type => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 1,
},
position => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
location => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
description => {
data_type => 'TEXT',
is_nullable => 0,
},
how_to_apply => {
data_type => 'TEXT',
is_nullable => 0,
},
token => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
is_public => {
data_type => 'TINYINT',
is_nullable => 0,
default_value => 1,
},
is_activated => {
data_type => 'TINYINT',
is_nullable => 0,
default_value => 0,
},
email => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
expires_at => {
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
},
created_at => {
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
},
updated_at => {
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
},
);
プライマリキーや、INDEX なども定義しましょう:
__PACKAGE__->set_primary_key('id');
__PACKAGE__->add_unique_constraint(['token']);
以上で Job テーブルの定義はとりあえず完了です。ファイルの全体はこのようになっています。
package Jobeet::Schema::Result::Job;
use strict;
use warnings;
use parent 'Jobeet::Schema::ResultBase';
__PACKAGE__->table('jobeet_job');
__PACKAGE__->add_columns(
id => {
data_type => 'INTEGER',
is_nullable => 0,
is_auto_increment => 1,
extra => {
unsigned => 1,
},
},
category_id => {
data_type => 'INTEGER',
is_nullable => 0,
extra => {
unsigned => 1,
},
},
type => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 1,
},
position => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
location => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
description => {
data_type => 'TEXT',
is_nullable => 0,
},
how_to_apply => {
data_type => 'TEXT',
is_nullable => 0,
},
token => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
is_public => {
data_type => 'TINYINT',
is_nullable => 0,
default_value => 1,
},
is_activated => {
data_type => 'TINYINT',
is_nullable => 0,
default_value => 0,
},
email => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
expires_at => {
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
},
created_at => {
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
},
updated_at => {
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
},
);
__PACKAGE__->set_primary_key('id');
__PACKAGE__->add_unique_constraint(['token']);
1;
同様に他のテーブルクラスを定義していきましょう。 Categoryクラス:
package Jobeet::Schema::Result::Category;
use strict;
use warnings;
use parent 'Jobeet::Schema::ResultBase';
__PACKAGE__->table('jobeet_category');
__PACKAGE__->add_columns(
id => {
data_type => 'INTEGER',
is_nullable => 0,
is_auto_increment => 1,
extra => {
unsigned => 1,
},
},
name => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
);
__PACKAGE__->set_primary_key('id');
__PACKAGE__->add_unique_constraint(['name']);
1;
CategoryAffiliate クラス:
package Jobeet::Schema::Result::CategoryAffiliate;
use strict;
use warnings;
use parent 'Jobeet::Schema::ResultBase';
__PACKAGE__->table('jobeet_category_affiliate');
__PACKAGE__->add_columns(
category_id => {
data_type => 'INTEGER',
is_nullable => 0,
extra => {
unsigned => 1,
},
},
affiliate_id => {
data_type => 'INTEGER',
is_nullable => 0,
extra => {
unsigned => 1,
},
},
);
__PACKAGE__->set_primary_key(qw/category_id affiliate_id/);
1;
Affiliate クラス:
package Jobeet::Schema::Result::Affiliate;
use strict;
use warnings;
use parent 'Jobeet::Schema::ResultBase';
__PACKAGE__->table('jobeet_affiliate');
__PACKAGE__->add_columns(
id => {
data_type => 'INTEGER',
is_nullable => 0,
is_auto_increment => 1,
extra => {
unsigned => 1,
},
},
url => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
email => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
token => {
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
},
is_active => {
data_type => 'TINYINT',
is_nullable => 0,
default_value => 0,
},
created_at => {
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
},
);
__PACKAGE__->set_primary_key('id');
__PACKAGE__->add_unique_constraint(['email']);
1;
これですべてのテーブルのカラム定義が完了しました。慣れていないと面倒に感じるかもしれません。
これらの定義方法は DBIx::Class::ResultSource のドキュメントにまとめられていますので、慣れないうちはそれを見ながら定義すると良いでしょう。
また、使用頻度の高い定義に関しては、定数関数用のモジュールを作ってそれを読み込んで使っても良いでしょう。
package Jobeet::Schema::Types;
use parent 'Exporter';
our @EXPORT = qw/PK_INTEGER INTEGER VARCHAR TINYINT DATETIME/;
sub PK_INTEGER {
+{
data_type => 'INTEGER',
is_nullable => 0,
is_auto_increment => 1,
extra => {
unsigned => 1,
},
@_,
};
}
sub INTEGER {
+{
data_type => 'INTEGER',
is_nullable => 0,
extra => {
unsigned => 1,
},
@_,
};
}
sub TINYINT {
+{
data_type => 'TINYINT',
is_nullable => 0,
default_value => 0,
extra => {
unsigned => 1,
},
@_,
};
}
sub VARCHAR {
+{
data_type => 'VARCHAR',
size => 255,
is_nullable => 0,
@_,
},
}
sub DATETIME {
+{
data_type => 'DATETIME',
is_nullable => 0,
timezone => Jobeet::Schema->TZ,
@_,
};
}
1;
package Jobeet::Schema::Result::Affiliate;
use strict;
use warnings;
use parent 'Jobeet::Schema::ResultBase';
use Jobeet::Schema::Types;
__PACKAGE__->table('jobeet_affiliate');
__PACKAGE__->add_columns(
id => PK_INTEGER,
url => VARCHAR,
email => VARCHAR,
token => VARCHAR(
size => 80,
),
is_active => TINYINT,
created_at => DATETIME,
);
__PACKAGE__->set_primary_key('id');
__PACKAGE__->add_unique_constraint(['email']);
1;
こんな風にすっきり書くことができます。
さて、カラム定義は完了しましたが足りない物があります。そうです、リレーションの定義です。最初のリレーションモデルの図を思い出してください。
リレーションの定義を追加してみましょう。Job と Categoryは1対多の関係にあることがわかりますか? このような関係の場合はまず Job クラスに
__PACKAGE__->belongs_to( category => 'Jobeet::Schema::Result::Category', 'category_id' );
次に、Category クラスに
__PACKAGE__->has_many( jobs => 'Jobeet::Schema::Result::Job', 'category_id' );
と定義します。この belongs_to と has_many のセットが1対多のリレーションを表しています。これらは必ずセットで定義するようにしてください。
Category と Affiliate の関係はどうでしょう。これは CategoryAffiliate をマッピングテーブルとした多対多のリレーションモデルです。このような場合はまず、それぞれ直接リレーションしているテーブル同士の 1対多のリレーションを定義します。
Category:
__PACKAGE__->has_many(
category_affiliate => 'Jobeet::Schema::Result::CategoryAffiliate', 'category_id');
Affiliate:
__PACKAGE__->has_many(
category_affiliate => 'Jobeet::Schema::Result::CategoryAffiliate', 'affiliate_id' );
CategoryAffiliate:
__PACKAGE__->belongs_to(
category => 'Jobeet::Schema::Result::Category', 'category_id' );
__PACKAGE__->belongs_to(
affiliate => 'Jobeet::Schema::Result::Affiliate', 'affiliate_id' );
そして、Category から Affiliate への多対多のリレーション、また反対の Affiliate から Category への多対多のリレーションを定義します。
Category:
__PACKAGE__->many_to_many( affiliates => category_affiliate => 'affiliate' );
Affiliate:
__PACKAGE__->many_to_many( categories => category_affiliate => 'category' );
リレーションに関する注意点
各リレーションメソッドは、第4引数にハッシュリファレンスを渡すことで細かい設定を追加することが可能です。
is_foreign_key_constraint
リレーションを正しく定義すると、出力される DDL にも適宜外部キー制約等を付加してくれます。
これは非常に優れものなのですが、困ったことに、MySQLは 外部キーが作成されるときに、参照元の列でインデックスを自動的に生成 してしまいます。
御存知の通り、過剰なインデックスはINSERT処理等を重くする原因となるので、場合によっては、 外部キー制約を DB に定義したくない場合があるでしょう。
また、単体テストを書くときに、外部キー制約が枷になって、テストケース毎に膨大で煩雑なフィクスチャが必要になってしまう ことを避けたい場合も外部キー制約を DB に定義したくない場合があるでしょう。
そういった場合は、リレーションメソッドの第3引数に、 is_foreign_key_constraint => 0 を指定してみてください。
DDL には外部キー制約が付加されませんが、ORM上では正しくメソッドをたどることができます。
cascade_delete
恐ろしいことに has_many リレーションメソッドはデフォルトでは、レコードの削除及び更新をcascade(連鎖)します。
データの整合性を保つという点では、望ましい挙動なのかもしれませんが、一般的に DELETE 文は低速であり、簡単に アプリケーションのボトルネックとなり得ます。大規模なアプリケーションでそれが連鎖なんてしようものなら大変です。
例えば、Userデータが削除されたら、それに紐付くリレーションが一斉に削除されるだなんて想像もしたくありません。
この挙動を防ぐために、リレーションメソッドの第3引数にcascade_delete => 0 を指定することができます。
(もちろん DELETE 文がなるべく発行されないようなアプリケーションを作ることが肝要です。)
上記のオプションをまとめて指定すると以下のようになります。
Category:
__PACKAGE__->has_many(
category_affiliate => 'Jobeet::Schema::Result::CategoryAffiliate', 'category_id',
{
is_foreign_key_constraint => 0,
cascade_delete => 0,
},
);
これでリレーションの定義も完了しました。
リレーションに関しての詳細は DBIx::Class::Relationship のドキュメントが詳しいです。
しかしまだ足りないものがあるのです、created_at や updated_at が自動的に更新されるようにするためにもう少しコードを足す必要があります。
Result クラスのベースクラス(Jobeet::Schema::ResultBase)にそのためのコードを足していきましょう。
sub insert {
my $self = shift;
my $now = Jobeet::Schema->now;
$self->created_at( $now ) if $self->can('created_at');
$self->updated_at( $now ) if $self->can('updated_at');
$self->next::method(@_);
}
sub update {
my $self = shift;
if ($self->can('updated_at')) {
$self->updated_at( Jobeet::Schema->now );
}
$self->next::method(@_);
}
insert と update という関数を定義しました。これらはそれぞれ INSERT と UPDATE の SQL が実行されるときに呼ばれるメソッドです。DBIx::Class ではこのようにいろいろなところに自分のコードを差し込むことが出来ます。
INSERT 時には created_at と update_at を更新し、UPDATE 時には updated_at のみを更新しているのがわかりますか? またすべてのテーブルがこれらのカラムをもっているわけではないので、can を使用してメソッドの存在をチェックしています。
お疲れ様でした、以上でデータベース定義はすべて終わりです。
InflateとDeflate
上記のDATETIME型で使われていますが、DBIx::ClassにはInflateという仕組みがあります。 DBのデータを、オブジェクトとして直接操作できるようにするというものです。
例えば、DBのカラムにJSON文字列を入れて、それを直接データ構造として扱いたい場合は以下のようになります。
(DBのカラムにJSONを入れるのはどうなのかという話はおいておきます。)
use JSON qw/to_json from_json/;
...
__PACKAGE__->inflate_column(
'json_column',
{
inflate => sub { my $p = shift; $p && from_json($p); },
deflate => sub { my $p = shift; $p && to_json($p); },
}
);
同じようなInflate処理を何箇所も記述する必要がある場合は、ResultBaseに共通メソッドを定義しておくと良いでしょう。
package Jobeet::Schema::ResultBase;
...
use JSON qw/to_json from_json/;
sub inflate_json_column {
my $pkg = shift;
my @columns = @_;
for my $column (@columns) {
$pkg->inflate_column(
$column,
{
inflate => sub { my $p = shift; $p && from_json($p); },
deflate => sub { my $p = shift; $p && to_json($p); },
}
);
}
}
package Jobeet::Schema::Result::Something
...
__PACKAGE__->inflate_json_column(qw/json_colummn1 json_colummn2/);
ORM からデータベースにアクセスする
Ark からこのモデルを使用するのは明日にして、今日はこのクラスのみを少し使ってみましょう。
以下のようなスクリプトを deploy.pl としてアプリケーションディレクトリに作ってみましょう。
use strict;
use warnings;
use lib 'lib';
use Jobeet::Schema;
my $schema = Jobeet::Schema->connect('dbi:SQLite:./test.db');
$schema->deploy;
そしてこれを実行してみてください。
$ perl deploy.pl
これはなにも出力されず終わるかもしれません。しかし同じディレクトリに test.db と言うファイルが出来ていませんか? このスクリプトは test.db という SQLite データベースを作成します。そしてそれは今日定義したテーブル定義も含まれます!
DBIx::Class は DBIC_TRACE と言う環境変数でどのような SQL が実行されているか確認することが出来ます。
いちど今作成した test.db を削除し、この環境変数とともにもう一度スクリプトを走らせてみましょう。
$ rm test.db
$ DBIC_TRACE=1 deploy.pl
うまくいっていればこのような出力がされるはずです:
CREATE TABLE jobeet_affiliate (
id INTEGER PRIMARY KEY NOT NULL,
url VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
token VARCHAR(255) NOT NULL,
is_active TINYINT NOT NULL DEFAULT '0',
created_at DATETIME NOT NULL
):
CREATE UNIQUE INDEX jobeet_affiliate_email ON jobeet_affiliate (email):
CREATE TABLE jobeet_category (
id INTEGER PRIMARY KEY NOT NULL,
name VARCHAR(255) NOT NULL
):
CREATE UNIQUE INDEX jobeet_category_name ON jobeet_category (name):
CREATE TABLE jobeet_job (
id INTEGER PRIMARY KEY NOT NULL,
category_id INTEGER NOT NULL,
type VARCHAR(255),
position VARCHAR(255) NOT NULL,
location VARCHAR(255) NOT NULL,
description TEXT NOT NULL,
how_to_apply TEXT NOT NULL,
token VARCHAR(255) NOT NULL,
is_public TINYINT NOT NULL DEFAULT '1',
is_activated TINYINT NOT NULL DEFAULT '0',
email VARCHAR(255) NOT NULL,
expires_at DATETIME NOT NULL,
created_at DATETIME NOT NULL,
updated_at DATETIME NOT NULL
):
CREATE INDEX jobeet_job_idx_category_id ON jobeet_job (category_id):
CREATE UNIQUE INDEX jobeet_job_token ON jobeet_job (token):
CREATE TABLE jobeet_category_affiliate (
category_id INTEGER NOT NULL,
affiliate_id INTEGER NOT NULL,
PRIMARY KEY (category_id, affiliate_id)
):
CREATE INDEX jobeet_category_affiliate_idx_affiliate_id ON jobeet_category_affiliate (affiliate_id):
CREATE INDEX jobeet_category_affiliate_idx_category_id ON jobeet_category_affiliate (category_id):
DBIx::Class ではこのように SQL を自動的に生成します。
このためにたった1種類のデータベース定義だけで MySQL、SQLite、PostgreSQL、Oracle、DB2、MSSQL などのさまざまなデータベースを作成・利用することが出来ます。
SQLite以外のデータベース環境が利用できる人は先ほどのスクリプトの connect 先を変更してもうまく動くか確かめてみてください。たとえば MySQL なら
my $schema = Jobeet::Schema->connect(
'dbi:mysql:database_name',
'username',
'password',
);
のようにかくだけで MySQL にテーブルが作られます。(データベースは存在している必要があります)
データベースができたので実際にアクセスしてみましょう。以下のようなスクリプトを書いてみてください。
use strict;
use warnings;
use lib 'lib';
use Jobeet::Schema;
my $schema = Jobeet::Schema->connect('dbi:SQLite:./test.db');
このコードは指定されたデータベースに接続し、その Schema オブジェクトを取得しています。 このコードを元にいろいろなコードを書いて ORM の動作を試してみましょう。connect 先は先のスクリプトで deploy したものなら何でもかまいません。可能であればいろいろなデータベースに接続して、ただしく動作するか確認してみてください。
my $category_rs = $schema->resultset('Category');
とすると Category テーブルの ResultSet クラスを取得できます。これは Result クラスの集合でしたね。
なにも条件を指定していないのでこの $category_rs クラスは Category テーブルにある Result クラスのすべての集合を表します。しかしまだデータを入れていないので 0 個の Result クラスの集合と言えます。
print $category_rs->count;
としてみましょう。予想通り 0 と言う出力が出ましたか?
データをいれるには create メソッドを使います。
my $category = $category_rs->create({
name => 'new category',
});
これで新しく 「new category」という名前が作られその Result オブジェクト(Jobeet::Schema::Result::Categoryオブジェクト)が帰ってきます。
この状態でさきほどの
print $category_rs->count
を実行してみましょう。1が帰りますね。
ResultSet クラスは他にもテーブルに対するさまざまな処理をすることができます。
my $new_rs = $category_rs->search({ name => 'new category' });
のように search メソッドで全体から条件マッチで絞り込んだ ResultSet をかえしたり、
my $new_rs = $category_rs->search({ }, { rows => 5, page => 1 });
のように 5 個ずつ取得した場合 1 ページ目となる ResultSet を返したりといった感じです。
ResultSet クラスからそれに属する Result クラスを取得するには
my $category = $category_rs->find('id');
とIDから引いたり
my @categories = $category_rs->all;
としたり、
while (my $category = $category_rs->next) {
...
}
とイテレータでまわしたりと言うことが出来ます。
Result クラスではそれを表す Row にたいしてさまざまな処理を行えます。
print $category->name;
などのように各カラムにはその名前のメソッドでアクセスできます。
$category->update({ name => 'new name' });
$category->delete;
などのようにデータを更新したり、データを削除したりも出来ます。
まだまだ機能はたくさん
ここで DBIx::Class のメソッドをすべて説明していたらいくら書いてもきりがありません。ここではこの辺にしておきましょう。
まだ余力がある方は、ResultSetクラスに関しては DBIx::Class::ResultSet のドキュメントを、Result クラスに関しては DBIx::Class::Row のドキュメントがそれぞれ参考になるでしょう。
また、以下の記事にDBIx::Classの使い方が単体でよくまとまっているので読んでおくと良いでしょう。
明日お会いしましょう
今日はここまでです。今日は DBIx::Class を使用したデータベースの使用方法を学習しました。
まだエネルギーが残っていたら、DBIx::Class のドキュメントを参照し今回説明しなかった使い方について理解を深めてください。そうでなければ気にせずによく寝てください。
明日は今日作成したデータベースのバージョニング、そして DBIx::Class モデルを Ark から使う方法について話します。